Case 1: Application not VM-aware
In these graphs, a customer reported that there was slowness in their
batch job at night. They were running it in a VMware environment and they had
allocated the hardware based on their vendor's recommendations.
The lead team member insisted that there wasn't enough network bandwidth and had
asked for an upgrade. But looking at their router link utilisation, they had
more than enough bandwidth during the job run. So upgrading the bandwidth would
not solve this issue.
The lead team member then insisted that the hardware had to be upgraded!
The server graphs however showed something very interesting.
Even though 4 CPUs were allocated, only 1 CPU was highly utilised during the
job run.
Checks confirmed that the application was not designed to run efficiently in a
VMware environment. 6 months later, the application developer optimised their
to work in a VMware environment and all the allocated CPUs were used in
parallel.
Our service and consultants will save you money and time by identifying which
problematic area to focus on and not do unnecessary costly upgrades.
Case 2: Disk usage trends
The SAP B1 server crashed and the reason was the server had run out of disk
space. The log files were huge and after it was cleared, the system could
start again.
But was the "root cause"?
After a few weeks, we took a look at the yearly graph, we discovered the
same growth pattern as in the weeks before it. If left unchecked, the
system would crash again in 11 months time.
The application team then wrote a script to clear old logs after every 2 weeks.
Our service highlights system trends as a pre-cursor to system failures.
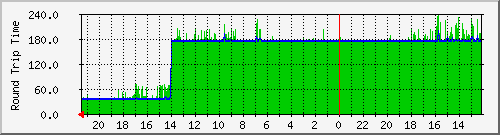
Case 3: Detect routing issues in ISP network
Looking at the latency trends, we saw that the latency has suddenly jumped up.
Going into the trace route reports, looking at the routes before/after the
latency jumped up, we could see that the routes were different.
This information was presented to the ISP concerned and they could quickly
revert to the old good route.
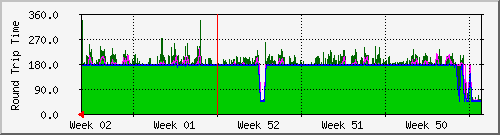
Case 4: Detect congestion issues in ISP provider's network
Looking at the latency trends, we saw that the latency has jumped up from the
start of wk 50 onwards and has remained up for many weeks.
If it was something that the ISPs were aware off, it would have been fixed by
now. The fact that the issue remained for so long meant that no one was aware
of the issue.
 The following report was sent to the ISP to show them location of problem;
the ISP's own internet provider within Singapore's Internet Exchange.
Start: Mon Jan 15 08:45:14 2018
HOST: gandalf Loss% Snt Last Avg Best Wrst StDev
1.|-- xxxx.xxxx.xxxx.xxxx 0.0% 3 0.6 0.6 0.4 0.6 0.0
2.|-- 1.192.75.138.unknown.m1.c 0.0% 3 6.2 3.9 2.6 6.2 2.0
3.|-- 242.246.65.202.unknown.m1 0.0% 3 2.4 2.5 2.4 2.9 0.0
4.|-- 241.246.65.202.unknown.m1 0.0% 3 2.5 2.7 2.2 3.4 0.0
5.|-- 162.246.65.202.unknown.m1 0.0% 3 32.5 13.9 2.7 32.5 16.2
6.|-- globe-telecom.sgix.sg.102 66.7% 3 174.8 174.8 174.8 174.8 0.0 <-PROBLEMATIC HOP
7.|-- 120.28.1.213 66.7% 3 176.3 176.3 176.3 176.3 0.0
8.|-- 120.28.9.33 0.0% 3 168.3 168.2 168.1 168.3 0.0
9.|-- 120.28.10.209 0.0% 3 171.1 171.0 170.9 171.1 0.0
10.|-- 120.28.4.158 0.0% 3 173.9 174.3 173.9 175.1 0.0
11.|-- yyyy.yyyy.yyy.yy 33.3% 3 175.6 175.4 175.3 175.6 0.0
The ISP worked with their counterparts and after some days, resolved the issue.
The following report was sent to the ISP to show them location of problem;
the ISP's own internet provider within Singapore's Internet Exchange.
Start: Mon Jan 15 08:45:14 2018
HOST: gandalf Loss% Snt Last Avg Best Wrst StDev
1.|-- xxxx.xxxx.xxxx.xxxx 0.0% 3 0.6 0.6 0.4 0.6 0.0
2.|-- 1.192.75.138.unknown.m1.c 0.0% 3 6.2 3.9 2.6 6.2 2.0
3.|-- 242.246.65.202.unknown.m1 0.0% 3 2.4 2.5 2.4 2.9 0.0
4.|-- 241.246.65.202.unknown.m1 0.0% 3 2.5 2.7 2.2 3.4 0.0
5.|-- 162.246.65.202.unknown.m1 0.0% 3 32.5 13.9 2.7 32.5 16.2
6.|-- globe-telecom.sgix.sg.102 66.7% 3 174.8 174.8 174.8 174.8 0.0 <-PROBLEMATIC HOP
7.|-- 120.28.1.213 66.7% 3 176.3 176.3 176.3 176.3 0.0
8.|-- 120.28.9.33 0.0% 3 168.3 168.2 168.1 168.3 0.0
9.|-- 120.28.10.209 0.0% 3 171.1 171.0 170.9 171.1 0.0
10.|-- 120.28.4.158 0.0% 3 173.9 174.3 173.9 175.1 0.0
11.|-- yyyy.yyyy.yyy.yy 33.3% 3 175.6 175.4 175.3 175.6 0.0
The ISP worked with their counterparts and after some days, resolved the issue.
 Start: Tue Jan 16 16:00:14 2018
HOST: gandalf Loss% Snt Last Avg Best Wrst StDev
1.|-- xxxx.xxxx.xxxx.xxxx 0.0% 3 0.5 0.6 0.5 0.6 0.0
2.|-- 1.192.75.138.unknown.m1.c 0.0% 3 2.7 2.6 2.5 2.7 0.0
3.|-- 242.246.65.202.unknown.m1 0.0% 3 2.4 2.4 2.4 2.5 0.0
4.|-- 241.246.65.202.unknown.m1 0.0% 3 2.9 2.6 2.4 2.9 0.0
5.|-- 162.246.65.202.unknown.m1 0.0% 3 2.6 13.3 2.5 34.8 18.6
6.|-- globe-telecom.sgix.sg.102 0.0% 3 2.9 2.9 2.8 3.0 0.0 <-RESOLVED
7.|-- 120.28.1.213 66.7% 3 31.1 31.1 31.1 31.1 0.0
8.|-- 120.28.9.33 0.0% 3 31.4 31.6 31.4 31.9 0.0
9.|-- 120.28.10.209 0.0% 3 34.5 34.4 34.3 34.5 0.0
10.|-- 120.28.4.158 0.0% 3 35.1 47.5 35.1 69.2 18.8
11.|-- yyyy.yyyy.yyy.yy 0.0% 3 35.3 35.4 35.3 35.5 0.0
It was not possible for the ISP to monitor route from their end as they're
in the centre of the communications path. However, the information from
EC1213 Networks probe at the customer's site was able to pin-point the
problematic area.
Without the information provided by EC1213 Networks systems, the problem would
still have persisted.
Start: Tue Jan 16 16:00:14 2018
HOST: gandalf Loss% Snt Last Avg Best Wrst StDev
1.|-- xxxx.xxxx.xxxx.xxxx 0.0% 3 0.5 0.6 0.5 0.6 0.0
2.|-- 1.192.75.138.unknown.m1.c 0.0% 3 2.7 2.6 2.5 2.7 0.0
3.|-- 242.246.65.202.unknown.m1 0.0% 3 2.4 2.4 2.4 2.5 0.0
4.|-- 241.246.65.202.unknown.m1 0.0% 3 2.9 2.6 2.4 2.9 0.0
5.|-- 162.246.65.202.unknown.m1 0.0% 3 2.6 13.3 2.5 34.8 18.6
6.|-- globe-telecom.sgix.sg.102 0.0% 3 2.9 2.9 2.8 3.0 0.0 <-RESOLVED
7.|-- 120.28.1.213 66.7% 3 31.1 31.1 31.1 31.1 0.0
8.|-- 120.28.9.33 0.0% 3 31.4 31.6 31.4 31.9 0.0
9.|-- 120.28.10.209 0.0% 3 34.5 34.4 34.3 34.5 0.0
10.|-- 120.28.4.158 0.0% 3 35.1 47.5 35.1 69.2 18.8
11.|-- yyyy.yyyy.yyy.yy 0.0% 3 35.3 35.4 35.3 35.5 0.0
It was not possible for the ISP to monitor route from their end as they're
in the centre of the communications path. However, the information from
EC1213 Networks probe at the customer's site was able to pin-point the
problematic area.
Without the information provided by EC1213 Networks systems, the problem would
still have persisted.
Read more info HERE
Live demo
Click HERE to see a live demo.
- Username: demo
- Password: demo